

TL;DR
Many organizations struggle to manage the issues of the current state vs the desired state and configuration drift in the deployment phase of the software development lifecycle (SDLC). Whether it’s a manual change on a server or the lack of tools to ensure that all environments are configured the same. In this post, you’ll learn how CloudTruth ensures every environment is configured perfectly.
The two biggest gripes that DevOps and application engineers have is dealing with deployment and consistency issues. Whether they’re deploying with CICD, in a GitOps workflow, or attempting to make sure that Staging and Production look the same, managing the desired state is always needed.
In this post, you’ll learn about the current state of SDLC deployments and how CloudTruth helps.
Where The Industry Currently Sits
Almost every engineering team in every organization, ranging from 10 employees to 5,000, has tech debt. Tech debt isn’t created maliciously. It’s usually something along the lines of “Yeah, implement that for now so we can move on to this more pressing matter and we’ll go back to fix that later.” The problem is, “later” usually never comes until it’s too late and kicking down everyone’s door.
Tech debt usually involves configuration data not being where it should be and a massive amount of configuration sprawl. For example, nearly every Sysadmin or DevOps engineer at some point has on the fly logged into a server to fix an issue that was hurting production. Just like almost every software developer has gone in and manually fixed some code in production without going through the proper channels. Although high fives and praise are going on at the moment, after the issue is fixed, the DevOps engineers and software developers are pulled in to fix another fire, which means they didn’t “fully” fix the actual problem that caused production to have issues.
This opens up two big problems:
- Deployment consistency
- The current state does not match the desired state.
Deployment Consistency
In the time before automation and repeatable techniques like CICD, organizations, if they were lucky, could push out 3-4 application updates per year. The remainder of the year was spent figuring out how to push the updates and preparing the platform to be able to handle it. Now, with CICD, we have the ability to push a button or push code to a repository, and it automatically kicks off a pipeline that does the work for us. However, there’s a problem – consistency isn’t met.
Because it’s so easy to push a button and the rest of the details are abstracted away from engineers, there are constant consistency issues with deployments. Whether it’s a Docker image that wasn’t built with the proper dependency for an environment or there weren’t enough ReplicaSets in a Kubernetes Manifest to handle the load, it seems like engineers are constantly changing parameters and environment variables on the fly without having one location that they can go to so they can see not only what the current values are, but an easy way to change those values.
Simply put, engineers are spending more than 70% of their time putting out fires because environments aren’t consistent and they have no way to manage the consistency. They’re spending time fixing issues that could be easily fixed from the start, reducing the majority of tech debt and making engineers much happier in their day-to-day work.
Engineers should spend a MAX of 40% of their time putting out fires and the rest of their time implementing value-driven work for the business. Teams need a way to save themselves the 40%.
Desired State vs Current State
Thinking about one of the high-level examples from the previous section – an engineer logging into a server, whether it’s SSH or RDP, and fixing some config file on the fly to make an application function properly. Although the issue is fixed, there’s a big problem here.
The problem is that now, the desired state doesn’t match the current state with new deployments. For example, let’s say that a CICD pipeline is used for deployments. Perhaps it’s running some Terraform code to create a pool of servers, and it creates two servers for an auto-scaling group. Then, a few weeks later, there’s a production issue. Engineers log in to troubleshoot and it turns out that two servers aren’t enough for the load coming in, so they log into a portal and autoscale to three servers.
Here’s the thing – if that CICD pipeline runs again for another environment, it’ll only create two servers if the code wasn’t updated to ensure there were three servers instead of only two. That means that the desired state will not match the current state.
Instead, engineers need an easy way to set those values for each environment via parameters instead of having to worry about changing multiple configs just to get to the desired end result.
How CloudTruth Solves This Problem
With CloudTruth managing the config data, you never have to guess the correct parameter and secret values for each environment. You also don’t have to worry about setting manual values throughout environments, like Dev, Staging, QA, and Prod. Instead, you have one location to manage the values and can also compare values across multiple environments and track the changes automatically.
Below is a screenshot of parameters. These parameters exist for a specific CloudTruth project.
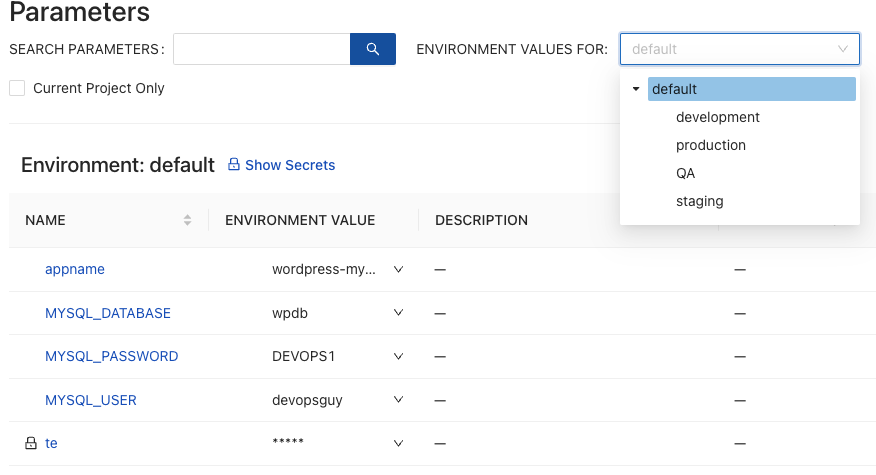
Under each parameter, you can either have a default value that goes across all environments, or you can set specific values for each environment. In any case, the parameter key still stays the same, and the value changes.

Then, you can use those values in any of your environments. It allows you to not only have one key/parameter name to call upon for every environment, but it allows you to have one template for every environment. For example, below is a Kubernetes Manifest. It’s one Kubernetes Manifest, but you can pass in multiple values.
Kustomize and Helm Charts are great, but where they fall short is not the ability to manage multiple environments, but the ability to have one file for every environment. For example, with Kustomize, you need to specify environments and have Value files for each environment. With Helm charts, you need a values.yaml file for each environment. That is many locations to manage parameters and environment variables.
Instead, CloudTruth gives you one location to change the values, and one location to see all of the new values.
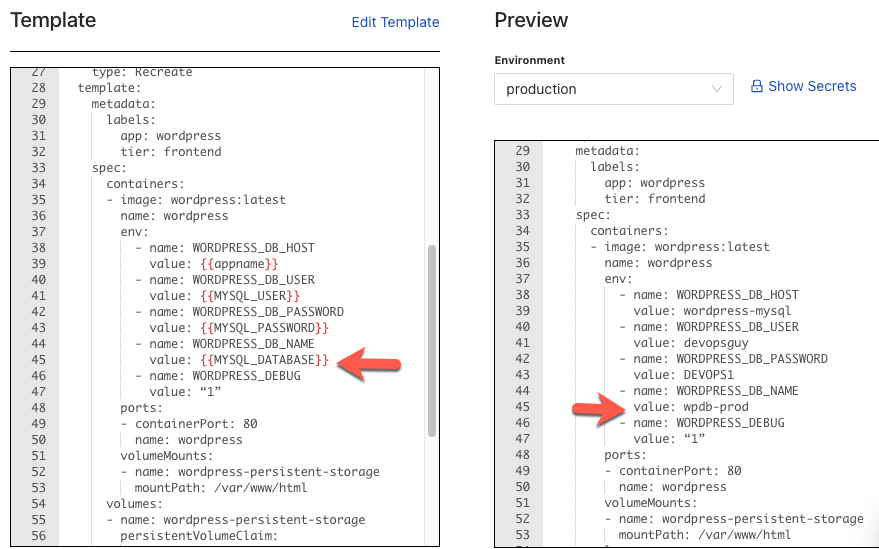
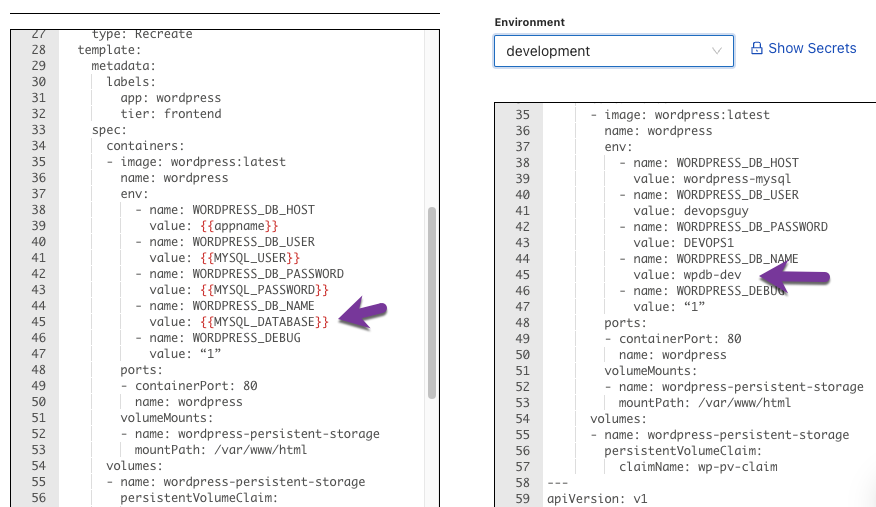
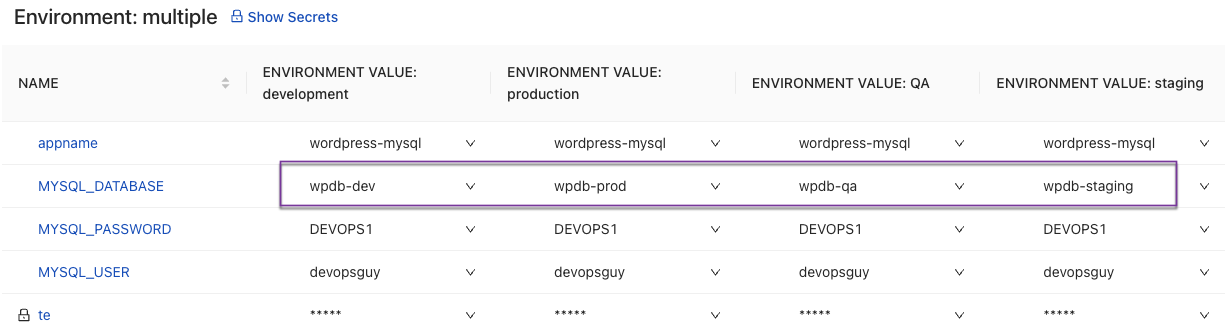
Once you set your values appropriately for each environment, you can compare each environment to confirm parameter values.
Wrapping Up
CloudTruth helped a customer increase deployment velocity by reducing the release cycle from two months to two weeks. This was an epic victory for both DevOps and App Devs teams. Deployment issues are typically caused by consistency issues, and utilizing a central configuration platform solves this problem.
This is how CloudTruth helps: keeping environments consistent.
Christian Tate, CEO of CloudTruth, says “know more, flow more”, and that’s what is being accomplished for customers.
Join ‘The Pipeline’
Our bite-sized newsletter with DevSecOps industry tips and security alerts to increase pipeline velocity and system security.


